
Engineering systems - Distributed Caching - I
#1.1: Deep dive into Facebook's Memcache and Uber's Cachefront for building a distributed caching system supporting billions of requests per second

Table of contents
Cache Aside
Read Through
Write around
Write through
What to expect in this article
This is Part I of a two part series deep diving into caching strategies used by Memcache, Cachefront and other caches to scale up reads and improve performance while maintaining tuneable consistency and reliability.
We’ll go through what caches are, why caches are required, and an in depth study of the different approaches taken to make caches more performant in different scenarios.
1. What is a cache?
A cache is an in-memory store commonly used for holding precomputed data, data that changes infrequently, and data that is queried frequently. Use cases include previously computed query results, database caches, api server caches, database query caches, OS disk caches, CDN. Since caches are in memory, they cannot store all the data which is stored in the primary storage nor provide durability. In-memory storage is more expensive than disk storage, so capacity of a cache is limited.
2. ….how then, are caches useful to us?
Data access patterns commonly follow the Pareto distribution ie, 80% of requests are served from 20% of the data. So it is indeed useful if we can store this 20% of data in cache to serve 80% of the traffic, reducing the query and compute load on the persistent data store and servers.
Caches also reduce the latency of the queries. Since cache is in memory, it is faster to retrieve data from it as compared to the Disk. To learn more about L1, L2 and memory caches, see this.
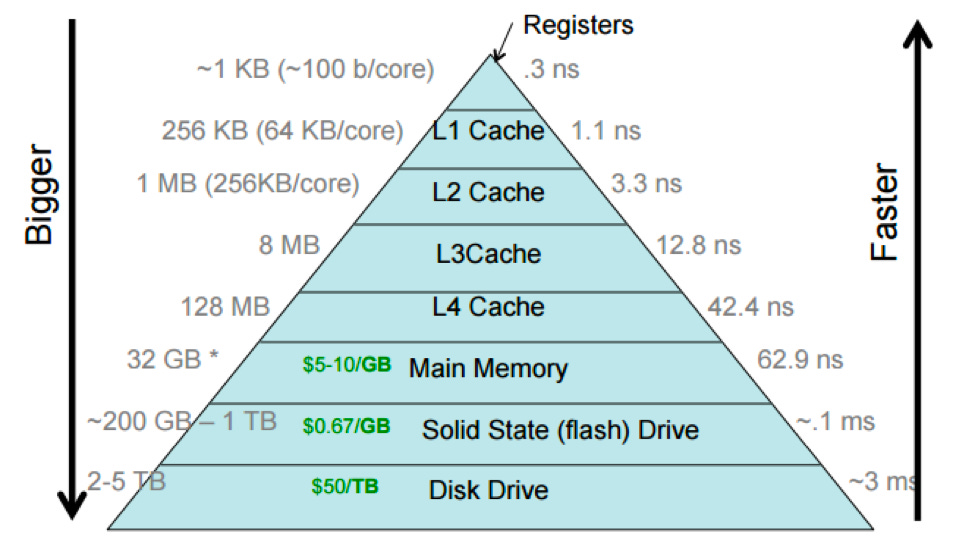
The cache in memory takes order of nanoseconds while random data fetched from disk takes order of milliseconds.
3. Caching Strategies
We can implement caching using several strategies for reads and writes.
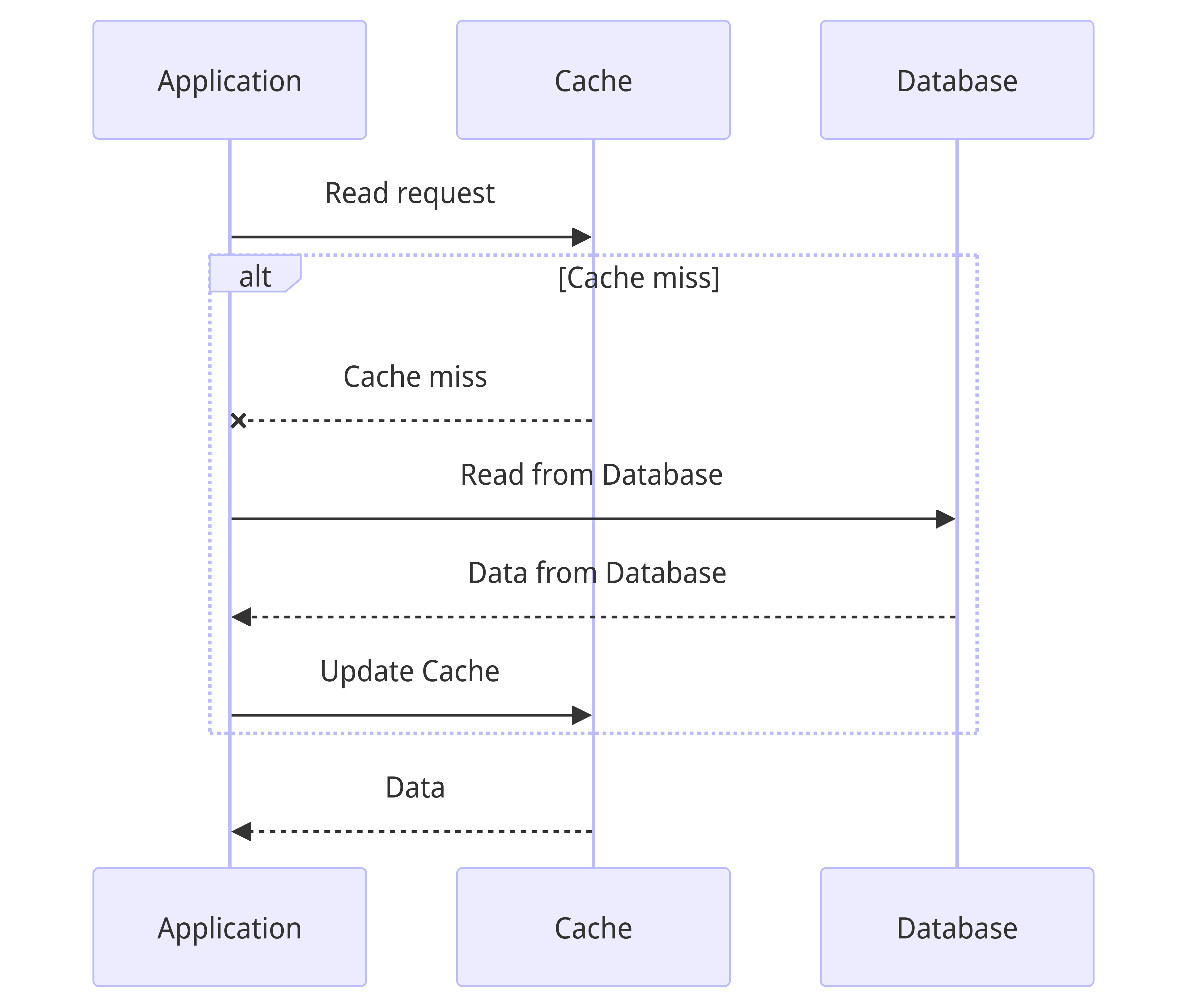
Cache Aside
In this strategy, for read requests, the application reads from the cache. In case of a cache miss, it reads from the database and updates the value in the cache.
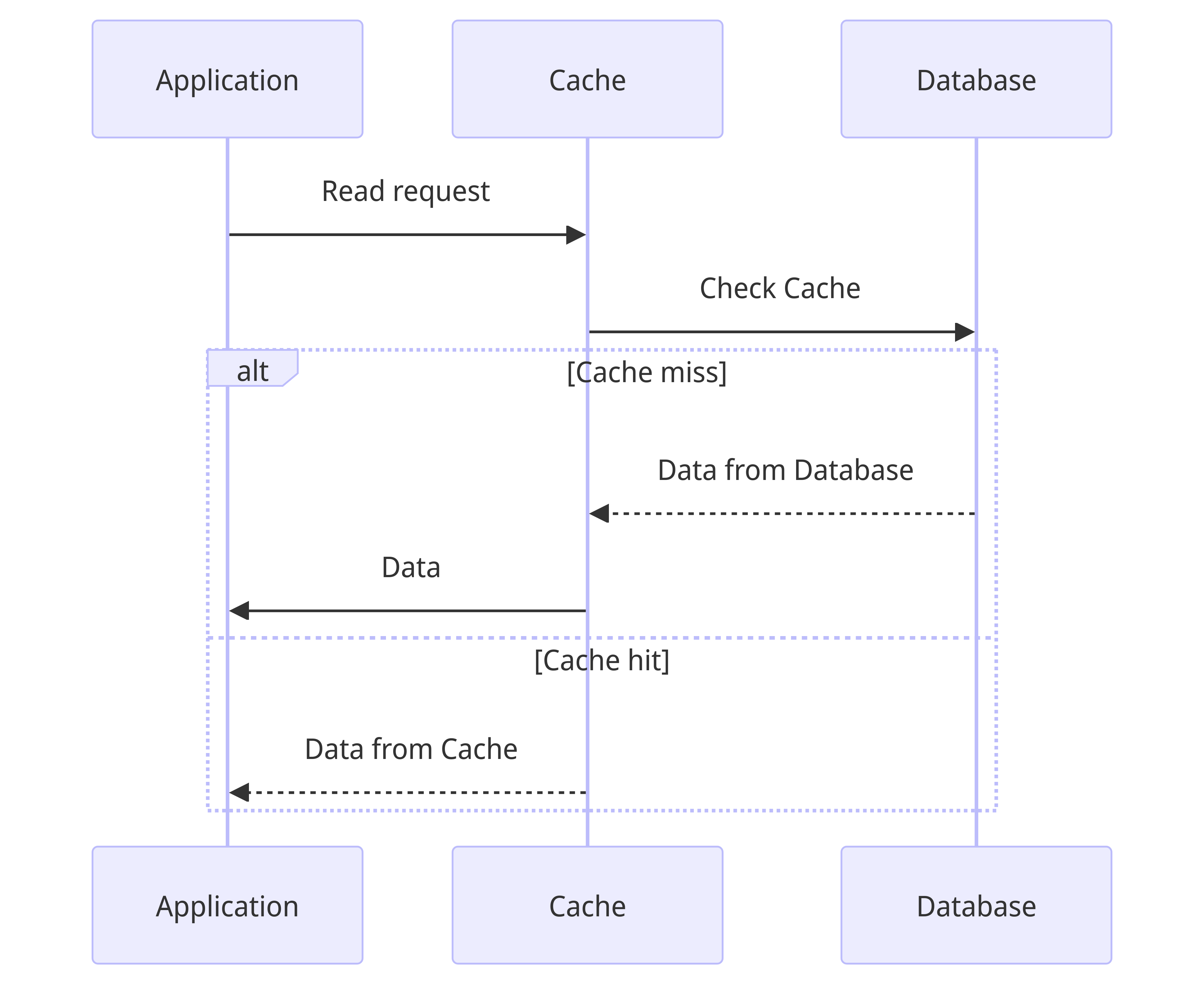
Read through
In this, the application relies on the cache as an intermediate for reads. The cache then checks if the data is present in it, otherwise it makes a database call and updates the cache, and returns the data to the application.
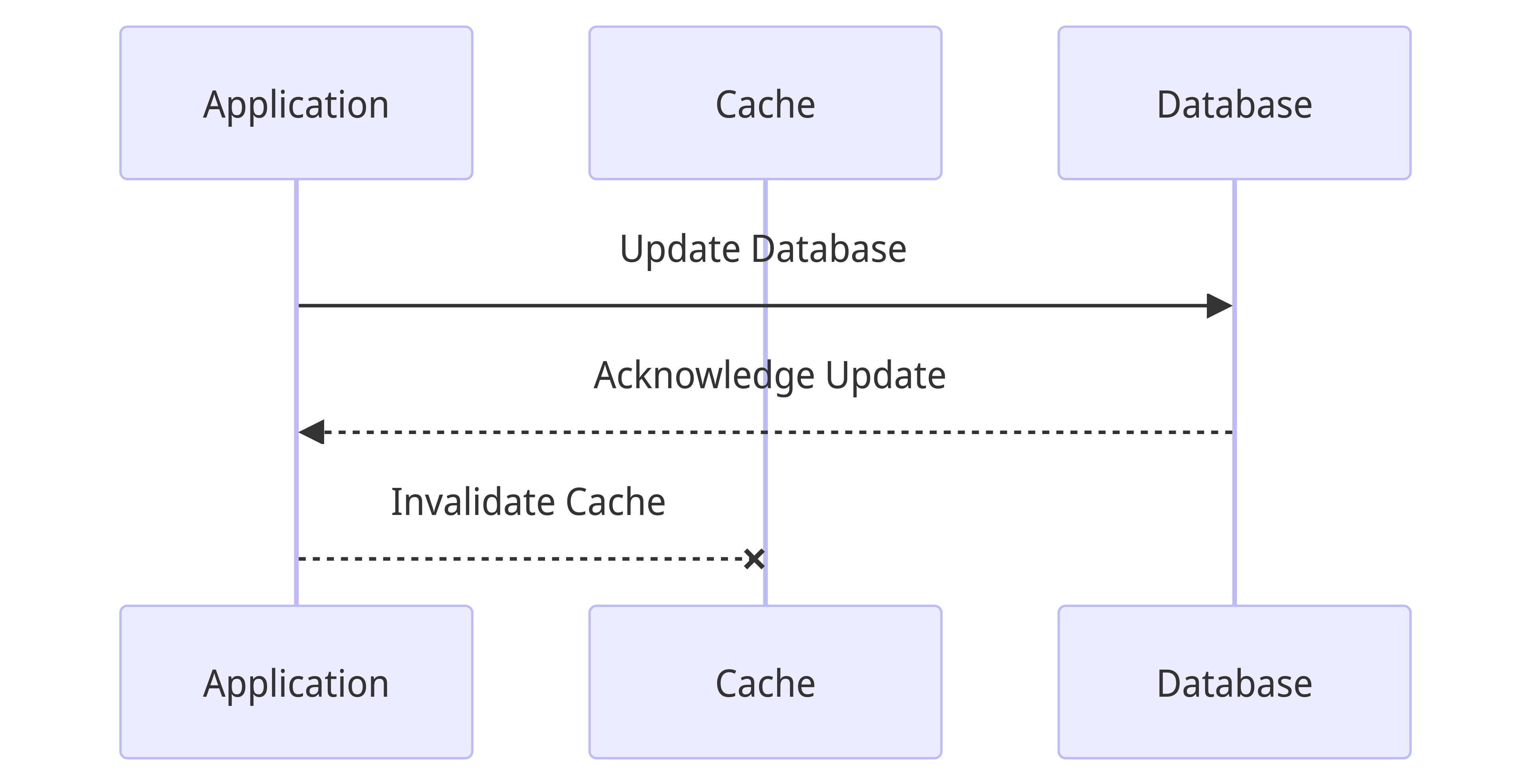
Write around cache
In this strategy, for write requests, the application first updates the database and correspondingly invalidates the keys in the cache.
Write through cache
The application relies on the cache for writes. All writes are issued to the cache, which updates the database and once it is updates, also updates the cache with the key/value.
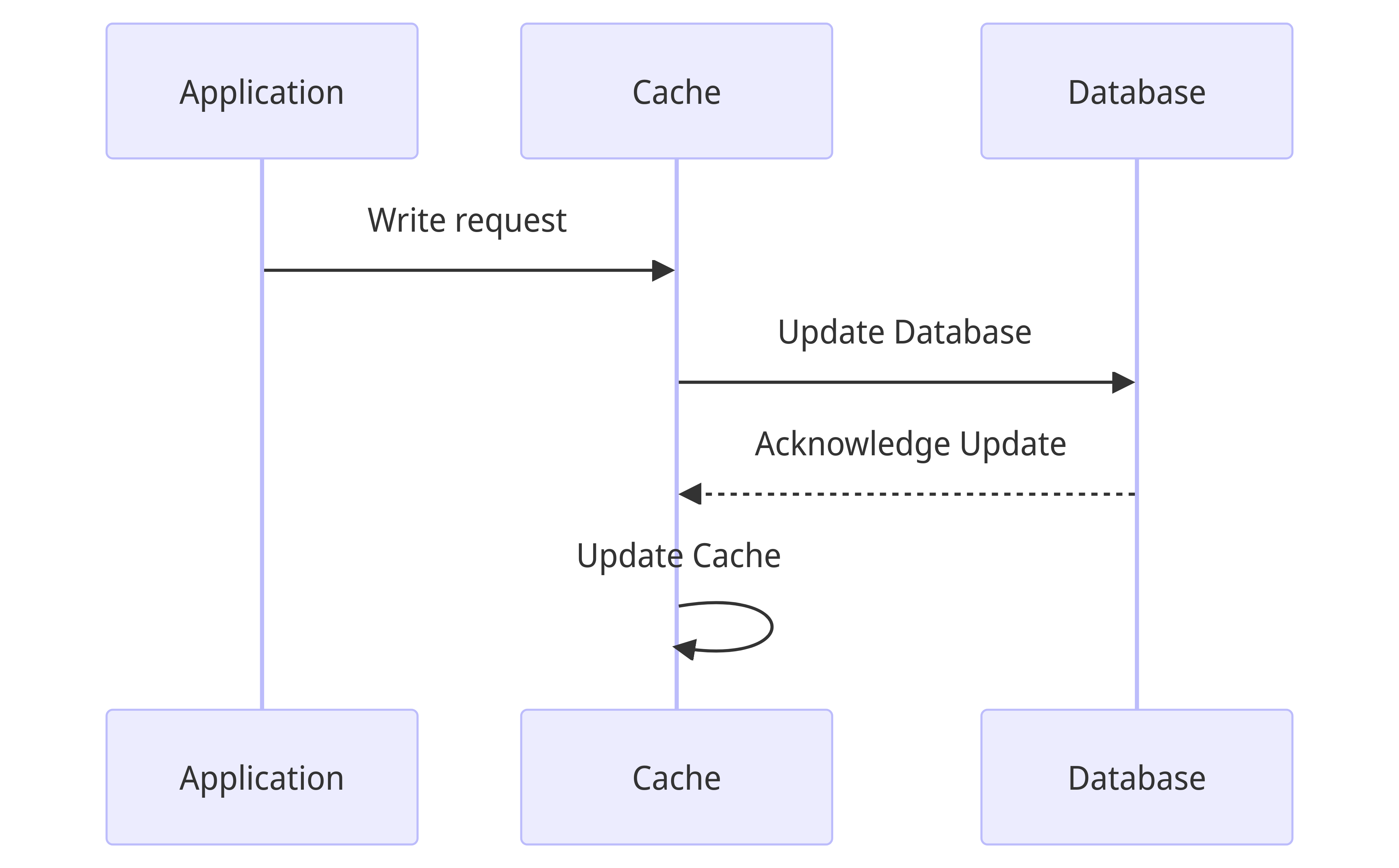
The Cache Aside and Write around strategies are used in combination by Memcached and Redis. For an in depth study of each caching strategy, check this.
4. Cache invalidation
We need to invalidate the stale keys in the cache so that our cache hit ratio
cache_hit_ratio = number_of_cache_hits / total_number_of_cache_requestsis optimised. There are various strategies that work according to the use case and pattern of data stored in the cache.
LRU cache: Invalidates/evicts the least recently used key in the cache.
LFU cache: Invalidates the least frequently used item in the cache.
TTL: Sets a TTL for each item in the cache, post which it is evicted
5. Designing a single node cache
A cache hosted on a single server would be very similar to a hash table (with a doubly linked list, in case of LRU). And indeed this is what Memcached and Redis internally use.
Cache requirements
It should be able to store value for a given key - set(key, value)
It should be able to retrieve value for a given key if stored previously - get(key)
It should be able to delete given key
It should be able to do these in O(1)
Further optimizations
automatically expand HashTable as the size increases, so that get and set are both still in constant time(Memcache) . Redis, on the other hand chains keys to the same bucket when there’s a conflict, and it performs a rehash when chains get too long.
handle concurrent requests by being multithreaded(Memcache) and using global locks for data access. In case of Redis, this is achieved by I/O multiplexing module, that monitors multiple sockets and returns the ones that are ready. This eliminates waits due to blocking on system calls. These ready sockets are pushed to a single threaded event loop.
separate ports for each UDP connection to reduce contention for sending read responses (Memcache)
6. Extending design to distributed cache
However, a single node's capacity for storing data is limited, and it presents a single point of failure. Hence, the focus shifts towards developing a distributed cache. In essence, this entails deploying multiple caching nodes, with each node responsible for storing a portion of the keys. We can have a cache client or proxy that decides which node will serve request (read/write) for a particular key. The simplest approach to decide the server the request should go to is
a modulo based algorithm ie, hashing the key and taking modulo with the number of servers. Simple enough.
function selectServer(key, numberOfServers):
// Hash the key to get a numerical value
hashedKey = hash(key)
// Perform modulo to determine server index
serverIndex = hashedKey % numberOfServers
return serverIndex
// Example usage:
key = "example_key"
numberOfServers = 5
selectedServer = selectServer(key, numberOfServers)Consistent Hashing
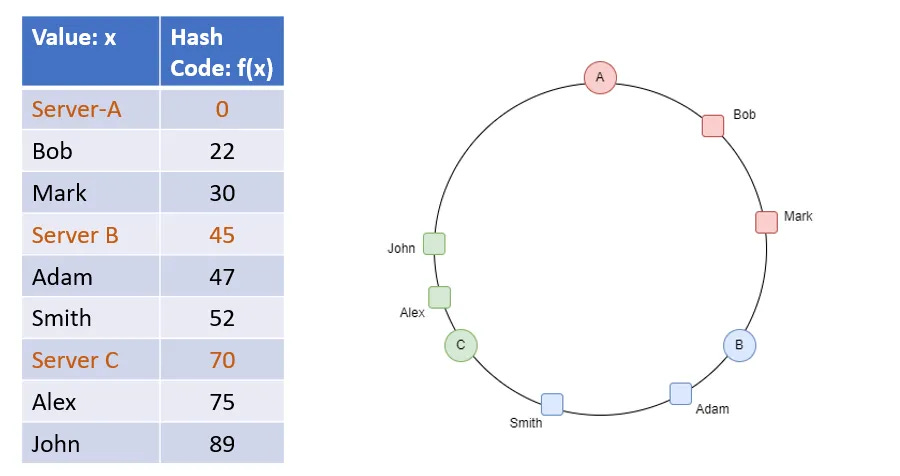
What if a node goes down? Or there’s too much traffic and we decide to add a node?We would need to redistribute data in that case. If we go by the modulo approach, it would result in all the data being redistributed. To avoid this, we then look at consistent hashing. In this approach, we take a virtual circle and arrange the nodes at different points in the circle. The hashed key lands on a point in the circle. We move clockwise to the next nearest node, and the request is served by this node.
# Define the nodes
nodes = ["A", "C", "E"]
# Function to perform binary search and find the next nearest/largest node
def find_next_nearest(key, nodes):
# Sort the nodes
sorted_nodes = sorted(nodes)
# Perform binary search
left = 0
right = len(sorted_nodes) - 1
next_nearest = None
while left <= right:
mid = (left + right) // 2
if sorted_nodes[mid] < key:
left = mid + 1
else:
next_nearest = sorted_nodes[mid]
right = mid
if next_nearest is None or next_nearest > "E":
return "A"
else:
return next_nearest
# Example usage
key = "Bob"
nearest_node = find_next_nearest(key, nodes)Now if we bring in another server B, only part of the data served by A would be redistributed to B. Similarly, if C goes down, the data previously being served by C would be served by E. So the data movement on server addition/removal is minimal.
This approach of distribution of data is called Consistent Hashing.
Auto service discovery / Cache cluster coordinator
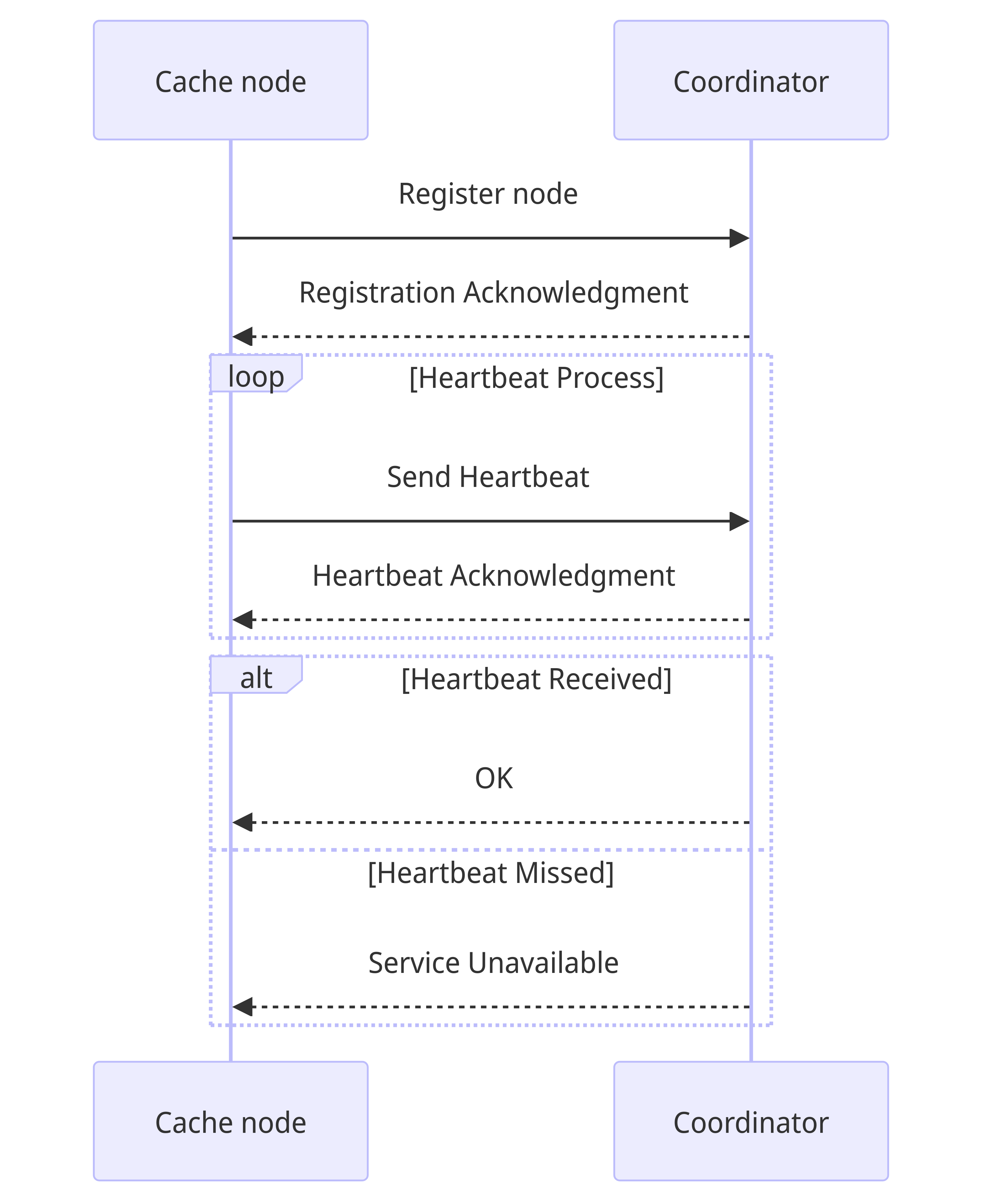
The cache cluster coordinator is responsible for monitoring the nodes in the cluster via a heartbeat mechanism. In this all the nodes of the cluster send a heartbeat to the coordinator which updates their corresponding last seen timestamp. If the last seen timestamp of a node is not updated in the coordinator even after x time duration, the node is considered as down, and coordinator requests for a new node to take its place.
Query Engine / Proxy layer
To maintain abstraction over the cache nodes in the cluster, we use a proxy layer (Query Engine in Cachefront) containing the logic to redirect to cache or database. In short this is the component that uses the cache aside mechanism to redirect cache misses to database and set cache for those updated keys. The query engine maintains a list of currently active hostnames and IP addresses (by syncing every x seconds with the coordinator) in order to know where to send the request for a particular key.
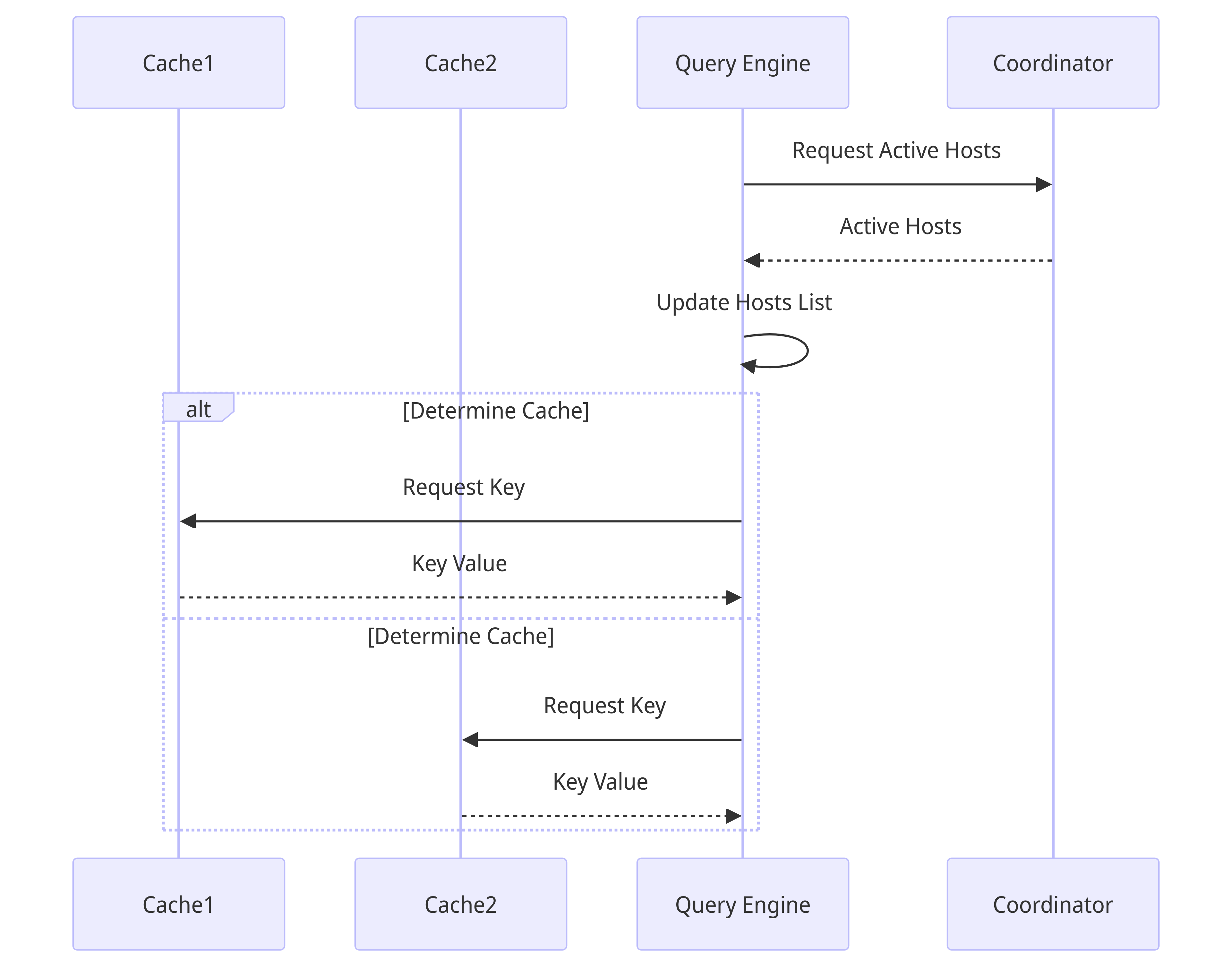
Memcache implements this as a dedicated proxy servers in each cluster, called McRouter that is responsible for routing, batching and sending parallel requests to the cache servers.
In the next part, we will dive into the different challenges that arise while maintaining a tuneable consistency as we need to replicate data within clusters and across regions, and how we make our cache resilient to heavy and bursty loads.
Congratulations for making it till the end of the article! Tune in for more in depth deep dives into system architectures.
Very informative and easy to understand.