

In this article we’ll discuss about how Kafka supports high throughput distributed streaming, the challenges faced, and the eventual improvements it has brought about in multiple KIPs.
In this particular article, we will discuss about
1. Table of Contents
What is Kafka
Why we use a distributed queue
How Kafka is implemented internally to support high throughput requirements of clients
Evolution of Kafka over the years
2. What is Kafka?
Kafka is a highly scalable, distributed messaging / queueing system with support for high throughput. Put simply, a messaging queue is an intermediate buffer for async communication between two components. Messages are stored on the queue until they are processed and deleted. A distributed queue has queues hosted in multiple server instances.
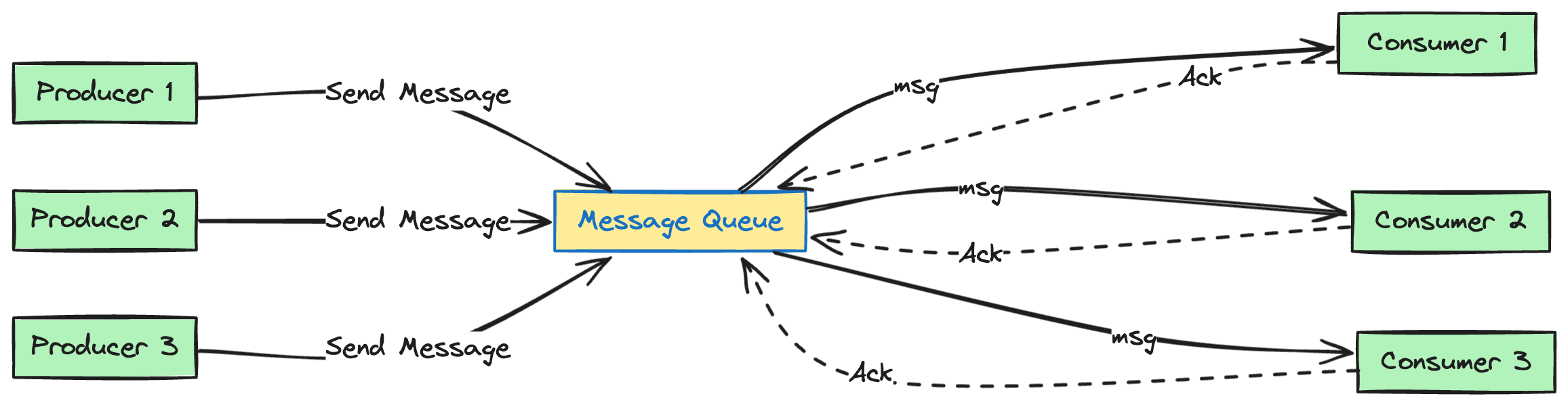
Kafka allows applications to consume messages in real time. The component sending or producing messages to the queue is called a producer. The component listening to or consuming the messages in the queue is called a consumer.
How are messages categorised?
The messages can be of different categories. The logical separation of messages according to their category is called topic. The producer sends messages to topics in the queue and the consumer can subscribe to multiple topics to receive messages from those topics.
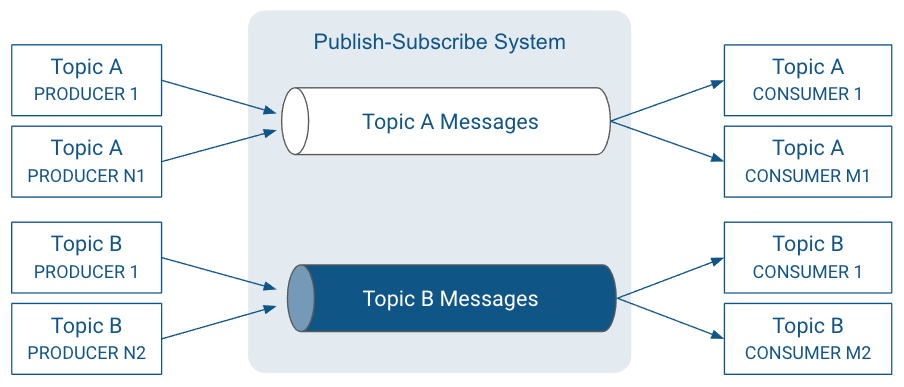
3. Why do we use a distributed messaging system?
to prevent coupling between two components of system
this helps in scaling out systems as producers and consumers can be scaled independently
to support asynchronous communication between components
this helps in producers not being aware of consumers and not waiting on acknowledgement from consumers
to let multiple components subscribe to particular messages
for real time consumption and processing of events as they occur
4. Kafka Internal Architecture
Let’s take a look at the requirements of distributed streaming platform.
Kafka needs to support high throughput logs from different producers
Should have distributed support - should be easy to partition and store messages on multiple machines
Should be performant with high loads - be highly scalable
Needs to replay all the messages from start on demand
FIFO guarantees for message ordering
Push vs Pull Mechanism
In a push based mechanism, the distributed queue push messages out as they come to the respective consumers. In a pull based system, the consumer has to poll the queue to fetch the messages.
💡 Kafka opts for a pull based mechanism rather than push based as adopted by other counterparts. This is because in case of high loads, the consumers can process messages without being overwhelmed. Also this supports the consumers with different capacity for processing messages at their own rate.
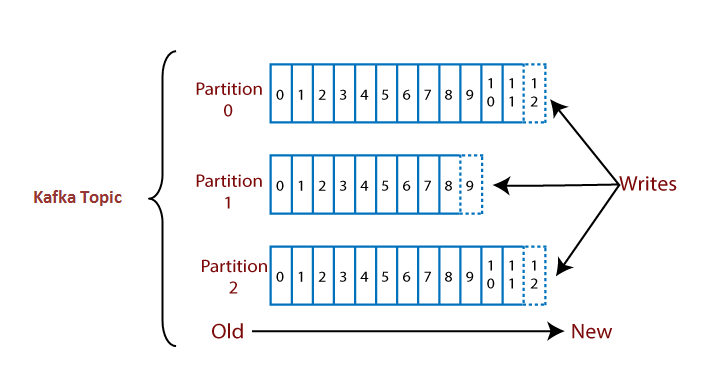
How are topics stored in Kafka?
A Kafka cluster has several brokers (servers). To handle high throughput, a topic has multiple partitions. Each broker stores one or more of these partitions of different topics.
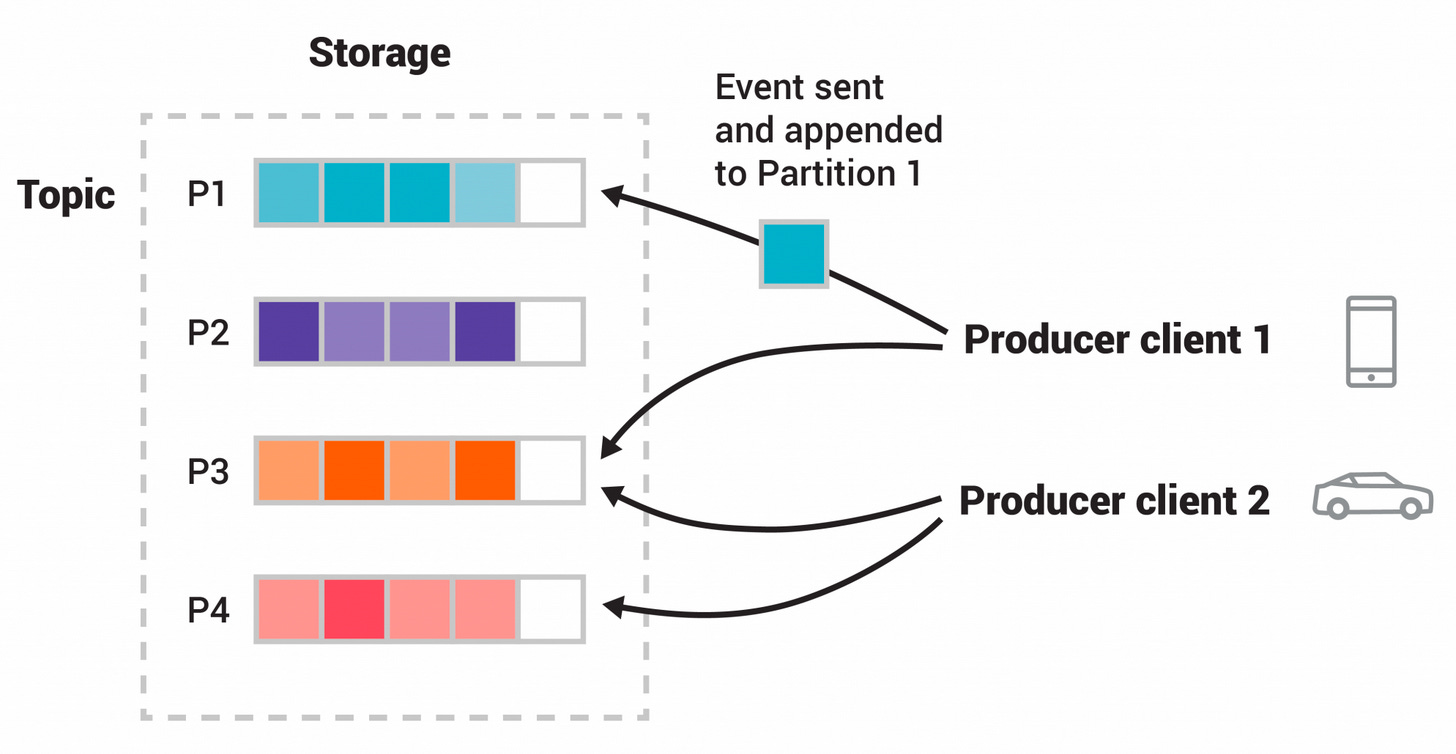
💡 Topics are distributed or sharded into different partitions which are stored in the Kafka brokers. A partition is the smallest unit of parallelism in Kafka. This means partitions can be consumed in parallel by consumers.
The messages in each partition are FIFO ordered, although there are no guarantees of FIFO ordering in messages across partitions. Each partition is read by a single consumer of a consumer group.
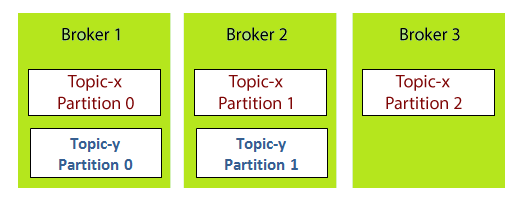
Each broker can have multiple partitions of different topics. Each partition is replicated in different brokers for durability.
How are the messages stored internally in Kafka?
Each partition stores log messages in append only segment files. When a producer publishes a message to a topic, the broker simply appends the message to the active segment file. These segment files are flushed to disk after a configurable time or after a size has reached. A consumer can consume the message only when it has been flushed to disk.
💡 All the messages are serialised into bytes and compressed in storage. So Kafka only deals with the raw bytes of data. This eliminates redundant serialisation and deserialisation latency and performance impact.
Caching in Kafka
Also Kafka does not employ a cache internally but relies on the OS page cache instead. Since Kafka servers can go down and that’d would lead to the Kafka cache needing to be warmed up again. So Kafka avoids double buffering by relying on the OS disk cache instead.
What’s the benefit of storing these in an append only log file?
💡 Sequential access in a rotating magnetic disk (HDDs) is extremely fast compared to the random access. Kafka brokers store the offsets of each of these segment files and when the consumer requests for an offset, it is able to locate the segment files and return the messages to the consumer.
The message offsets in the segment file are increasing but not consecutive, they are separated by the length of the messages. The consumer requests for an offset along with the number of bytes to fetch.
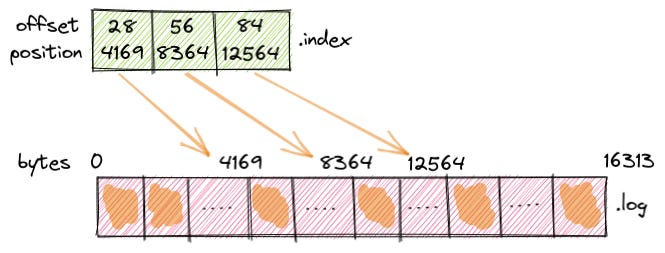
When the consumer acknowledges an offset, it means all the bytes in the segment file have been read by the consumer until that offset.
Serialization and desrialization happens scheme like avro schema registry or json etc.
How are these files sent to the consumer?
Typically getting the messages from disk and sending to the consumer consists of these steps:
retrieving the messages from disk according to the offset to the page cache in OS
copying the messages from OS page cache to the application buffer
copying the messages from application buffer to the kernel buffer
sending the kernel buffer to the consumer through the socket
💡 Kafka eliminates steps 2 and 3 by utilising the sendFile api in Unix systems. This allows the broker to directly send the bytes in a segment file to the consumer.
Retention of messages in Kafka
Since the broker does not store the consumer offsets, there is no way to know whether the message is safe to be deleted. So Kafka has a configurable retention period post which the message segments are deleted. This is 7 days by default but can be configured by setting the retention.duration.ms parameter. This also allows playback or rewind of messages from the start of the partition.
Consumers consuming from Kafka
Every consumer is typically a part of a consumer group. A Consumer Group has one or more consumers associated with it.
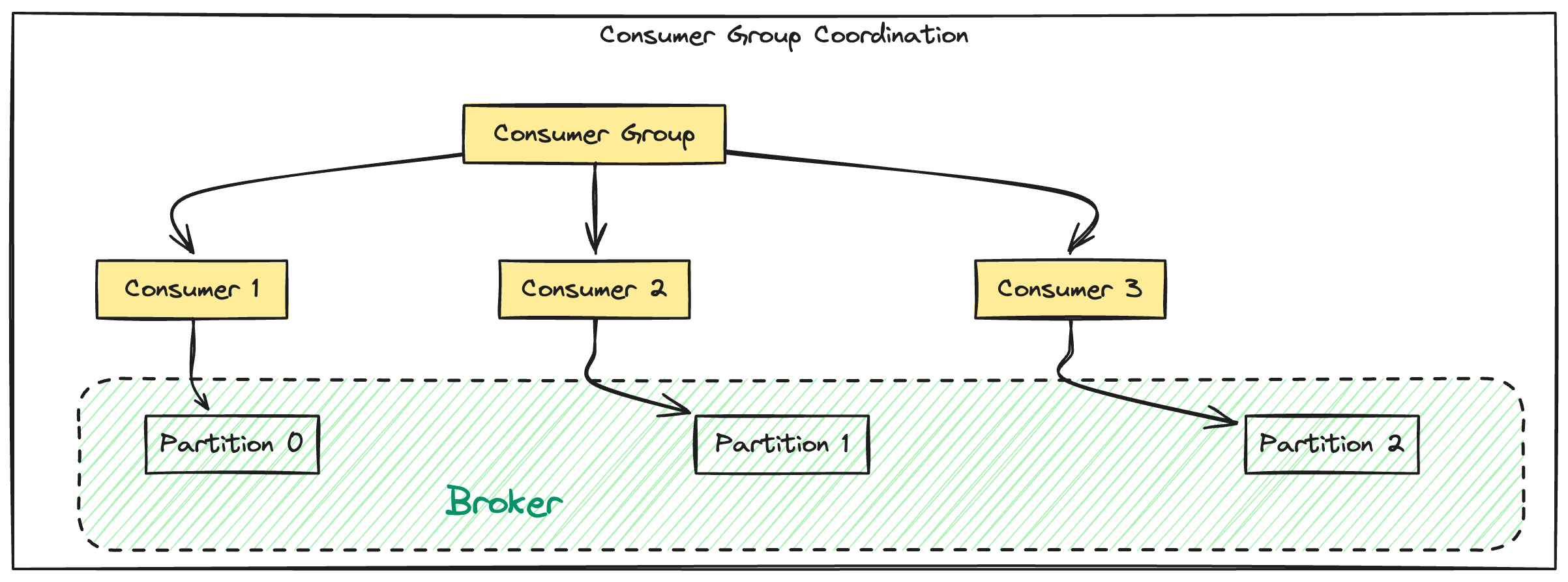
A topic is jointly read by consumers in a group. This means every message is consumed by a single consumer in the Consumer group.
💡 A partition is the smallest unit of parallelism in Kafka.
All consumers within a consumer group coordinate with each other so that messages in each partition of a topic is read by a single consumer in that group.
💡 This eliminates the need of locking messages and state maintenance overhead on a partition since two consumers of the same group cannot read from the same partition.
Consumers belonging to different consumer groups do not need to coordinate with each other.
Broker and Consumer Group Management
Kafka uses Zookeeper as a consensus system for distributed coordination. Zookeeper provides simple APIs to create, delete a path in it. It can be used to list a path or children of a given path.
The path can be configured to be persistent or ephemeral. In case a path is ephemeral, when the client who created the path is closed, the path is removed.
It also lets us configure watchers on certain paths or value of a particular path - which trigger an event on any change in the path.
It replicates data to multiple servers for durability and availability.
How Kafka uses Zookeeper
Offset registry for Consumer Group
This is the offset committed to Zookeeper by a consumer group for each topic partition path. After consuming messages of a partition, the consumer commits the new offset to this offset registry
It is stored persistently. If any consumer goes down, the new consumer can read check the offset of a partition from this registry and resume consuming
Ownership registry for Consumer Group
Each partition consumed by a consumer in a Consumer Group has a path in this registry
The value of the partition path is the id of the consumer who reads from this partition. This is stored ephemerally, so a consumer will lose its ownership of the partitions it reads from if the consumer becomes unavailable.
Consumer registry for consumers
When a consumer comes up, it registers itself as a member of a consumer group in the consumer registry. It also stores the topics it consumes from.
This is stored ephemerally. This means when the consumer goes down, this removes the associated consumer from this consumer group registry. Since there is a watcher in this path, it is what leads to a trigger of rebalance for the consumer group
Broker registry for brokers in Kafka
Whenever a broker is added, it registers itself with Zookeeper in the broker registry, adding the hostname, port, partitions and topics stored in it. This is stored ephemerally. In case broker goes down, all its partitions are automatically removed from the broker registry
Leader election for brokers
Leadership of brokers is maintained through zookeeper. It helps in electing leader for every partition of a topic
Each consumer adds a watcher on the broker registry and the consumer registry so it is aware of any changes in the broker and the consumers in the group.
Consumer Rebalancing
When a consumer goes down, we need to reallocate the partitions it was consuming from, to other consumers in the group. The watcher on the Zookeeper consumer group registry notifies the consumers of the group for the need of a rebalance. All the consumers surrender their partitions. The partitions are then freshly distributed and assigned to the consumer who update this in the ownership registry path. The consumers reads the offset for their partition from the offset registry in Zookeeper and start reading from that offset for the partition.
Avoiding Log Corruption
Kafka stores a CRC for every message that it stores to eliminate the possibility of log corruption. Kafka runs a recovery process for brokers if they run into I/O error. This recovery process removes all the messages with inconsistent CRC.
5. Evolution of Kafka through the years
Let’s discuss about how Kafka has evolved and improved over the years.
Better rebalancing
Each consumer surrendering its partition for the rebalance leads to a latency increase in the rebalance process. It is essentially a stop the world process. No consumers consume any messages during the rebalance process, which can be triggered by something like even pods addition or removal due to Kubernetes pod ASG autoscaling
The more the throughput of the topic, the more lag will be incurred by each consumer due to the rebalance process
Sticky assignors
As a part of improving this rebalance process, Kafka introduced sticky assignors that minimises partition movement by keeping as many EXISTING assignments of partitions to consumers as possible.
Incremental Cooperative Rebalancing
Due to these reasons, a KIP was proposed to reduce the latency in the rebalance process. This splits the rebalance process into sub tasks so that the consumers continue consuming data while these sub tasks are completed. Only the partitions that were revoked needed to be reassigned.
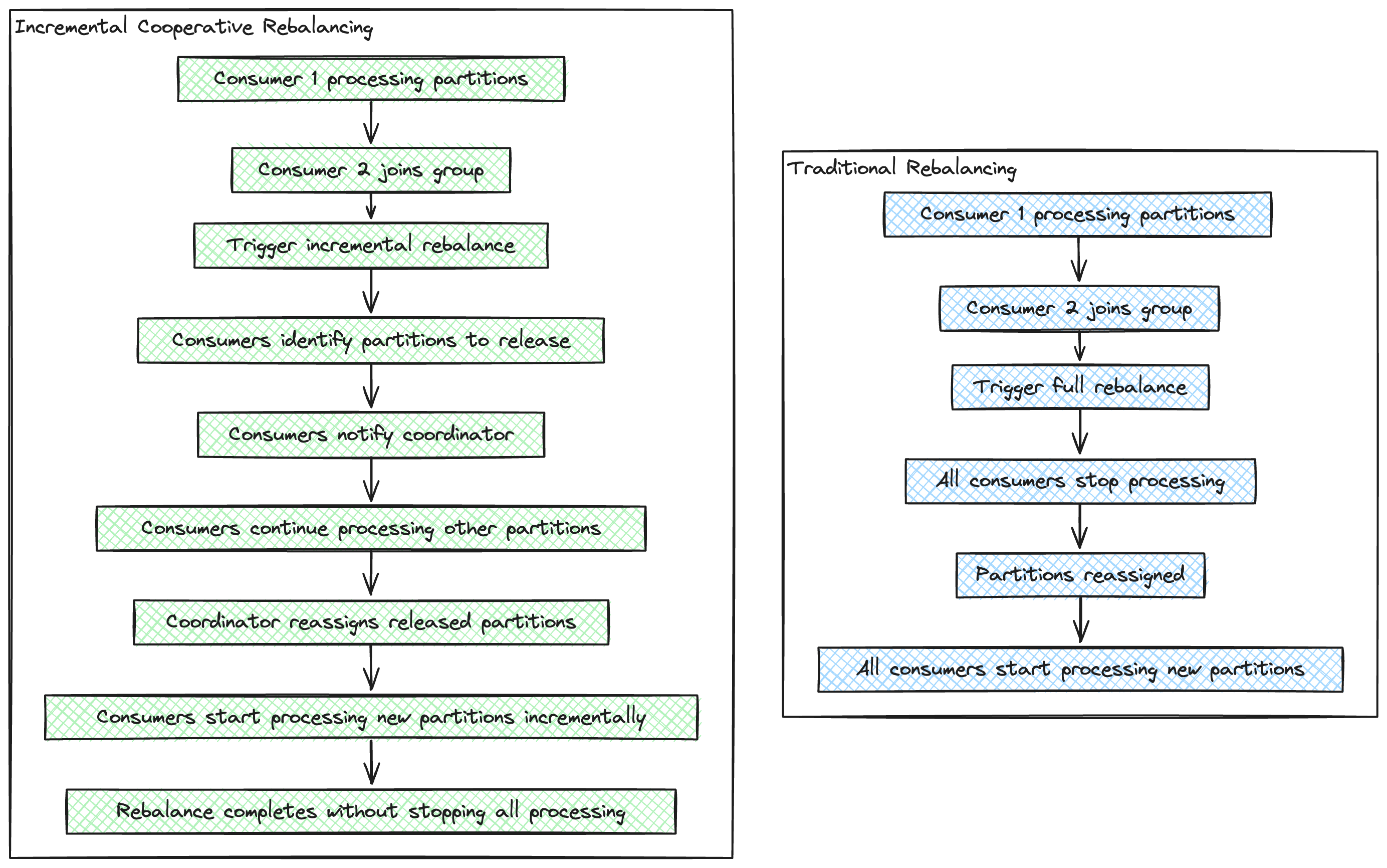
This happens in a two step process. The first step involves the revoking of required partitions from the consumer(s). The second step involves assigning this revoked partitions to the new consumers (during scale up) or rest of the consumers (scale down) in the group according to the load and capacity of the consumers.
Static Group Membership
In traditional kafka rebalances, the consumers are assigned an id when it joins a consumer group. In case the consumer disconnects for a short while and comes back, it gets a new id, which triggers a rebalance. This leads to higher latency and instability during rebalance.
In Static Group Membership, consumers are allowed to retain their id across rebalances so that if they’re down for a short while (session timeout) and then they come back up, they can retain their partitions without triggering a full rebalance.
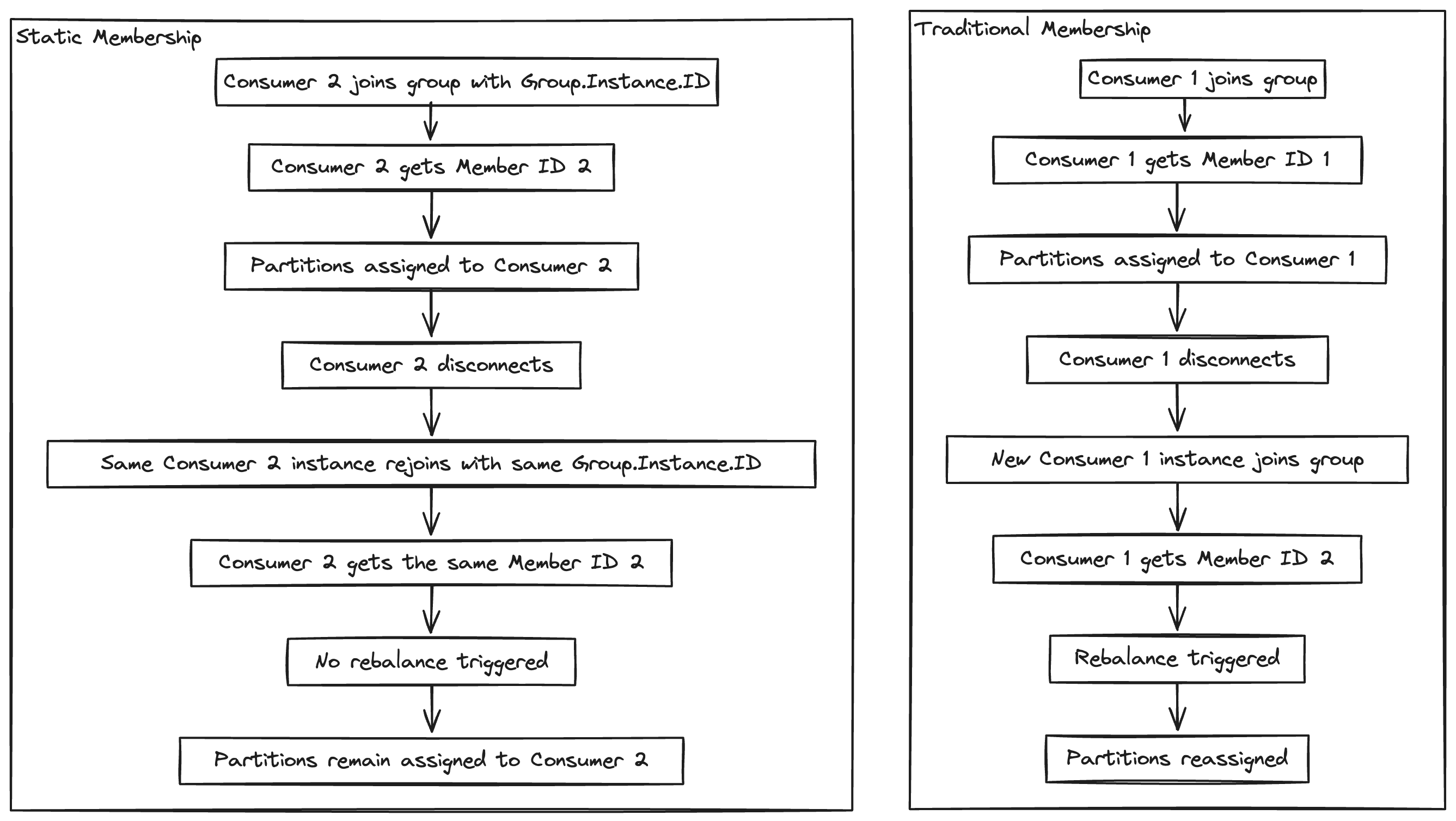
Support for durability and replication
What if a broker goes down? The messages stored in the partitions of the topics owned by that broker will be lost forever. To prevent this, Kafka replicates the partitions in different brokers for backup.
We have the concept of in sync replicas for each partition of a topic. Zookeeper maintains list of ISRs for every partition - ie the list of which replicas are in sync with the master partition.
References
Why stop the world when you can change it? (Incremental Cooperative rebalancing)
In the next article we will dive deep into Kafka Streams internals to see the innovations in streaming platforms.