
Engineering a Distributed Key Value Store
#2.1 : Lessons learnt from Amazon's DynamoDB (in 2022) and RocksDB on scaling up to support billion requests per second

Table of contents
The retrieval of data from the disk should be fast enough to meet our requirements… (Log Structured Merge Tree)
What if our server crashes before the Memtable is flushed to disk? (Write Ahead Logging)
How to quickly find if key exists in the SSTable of a level? (Bloom Filters)
How do we read the latest value of a key? (SSTables levelling)
What is a key value store?
A key-value store is a NoSQL database that stores values using keys. Keys are required to be unique and are mostly strings. Values can be of any type. Adding a value with an existing key updates the previous value. To retrieve data, you use the key to look up the stored value.
How is it different from relational databases?
Traditional relational databases store data in a structured form, and have a need of joins across tables. They also have requirement of transactions to guarantee strong consistency and ACID properties.
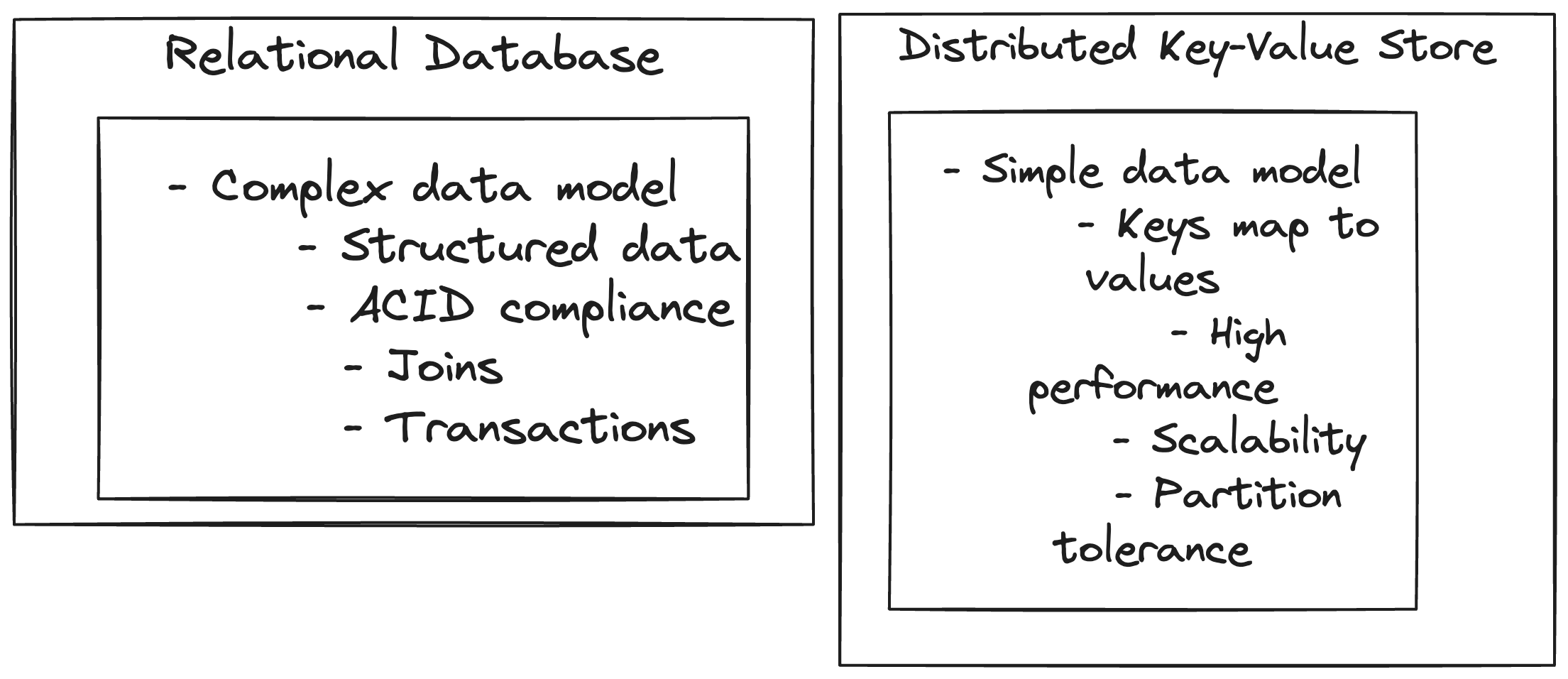
We use NoSQL databases like key value stores, most often for data that do not have a strict requirement for strong consistency. NoSQL databases prioritise availability over consistency. They most often have requirements for high write and read throughputs.
Requirements of a key value store
Let’s take a look at the primary and other requirements of a generic key value store.
Primary operations supported
put(key, value): Save a value against a key
get(key): Retrieve the value of a previously saved key
delete(key): Remove the key and its associated value from the database
Non functional requirements
High Throughput: Support millions of read and write requests per second
Low Latency: Ensure read and write operations complete in single-digit milliseconds
Configurable Consistency: Support both strong and eventual consistency
High Availability: Remain available at all times
Range Queries (Optional): Efficiently fetch values for a given range of keys
Single node key value store
For a key value store which is in memory, we can think of a simple hashmap to store all the values against their keys. However, this needs to be durable, so we can think of persisting this hashmap to disk at regular frequencies.
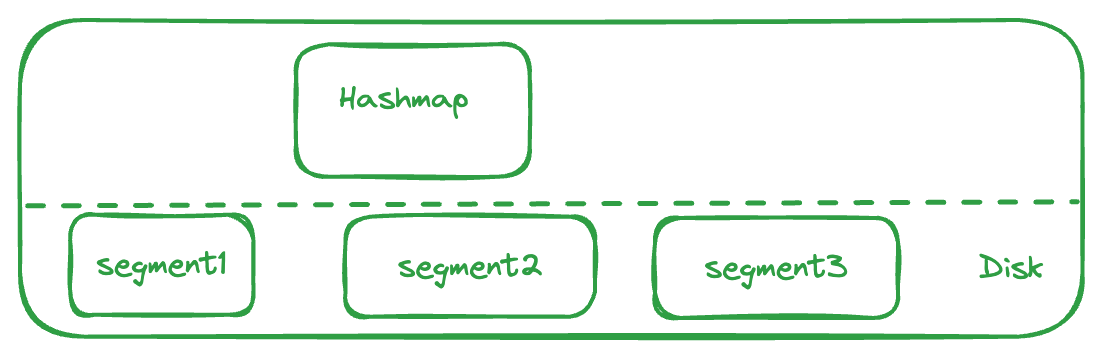
The retrieval of data from the disk should be fast enough to meet our requirements…
so keys cannot be stored simply on the disk. If they are stored randomly or in append only files, the position of all keys need to be tracked using an offset.
Another approach here would be to keep the keys in a sorted manner on disk and even in memory. Google’s Bigtable, RocksDB, Cassandra etc. follow this approach of maintaining the keys in Memtable, which is an in memory data structure containing the written data sorted by keys (using balanced binary tree or a skip list).
When the Memtable is full, the writes are serviced by a new Memtable and the previous Memtable is flushed to disk in a structure called SSTables (Sorted String Tables), which maintain these keys in a sorted manner. These SSTables are immutable.
This kind of structure (Memtable + SSTable) is called Log Structured Merge (LSM) tree.
What if our server crashes before the Memtable is flushed to disk?
The data would be lost. To avoid this, we maintain a Write Ahead Log (WAL) keeping track of all the requests that come in, in an append only format. So if the server crashes, we can spin up a new instance by applying all the operations as defined in the WAL.
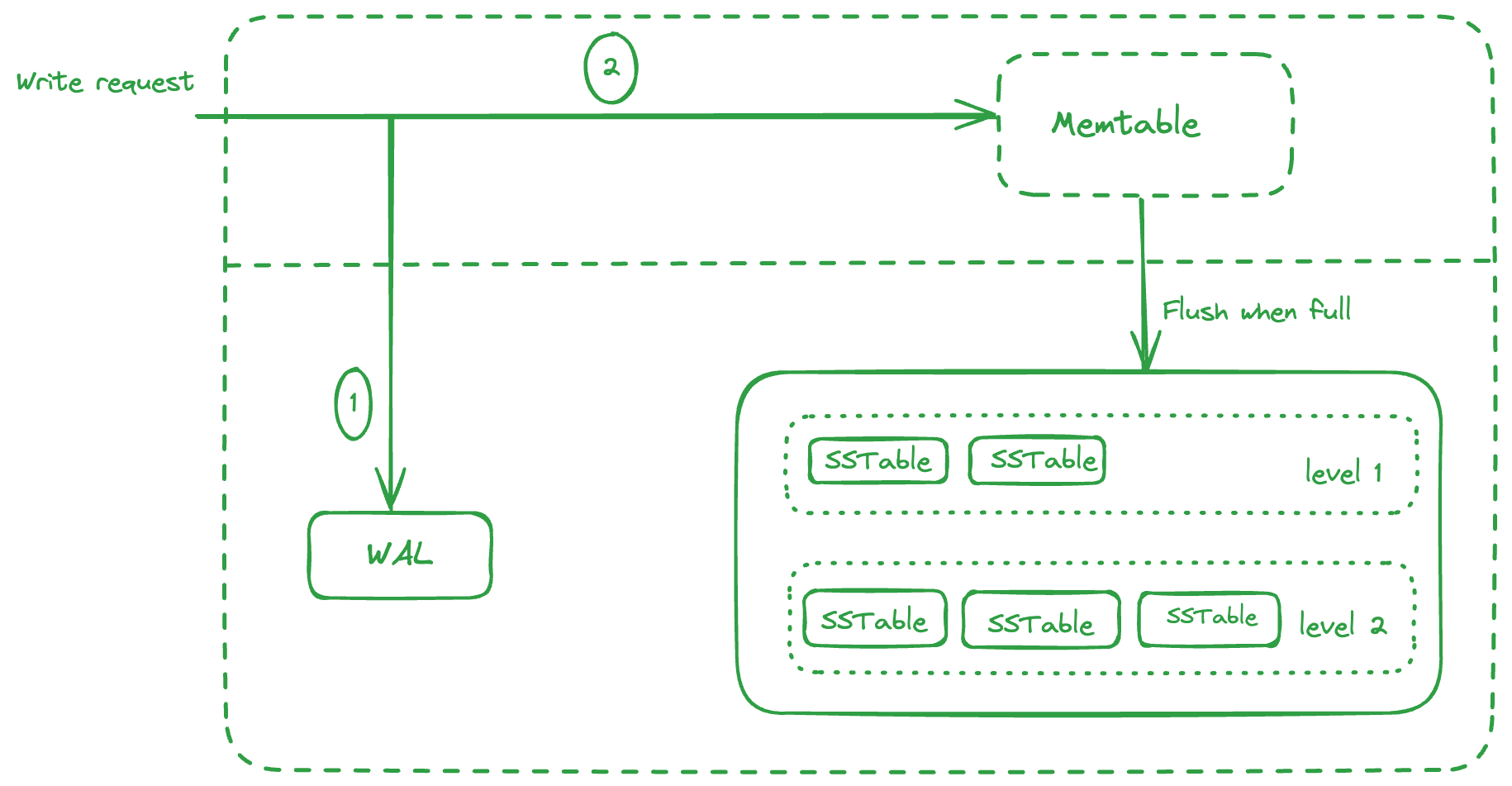
So when a write request comes in, it writes to the WAL followed by adding/updating the key/value in Memtable. When the Memtable is full, a new Memtable comes up for serving writes and the previous one is flushed to disk as an SSTable.
Also, a new WAL is used, and the previous one dropped as it the previous Memtable is already flushed to disk. Several SSTables form one level.
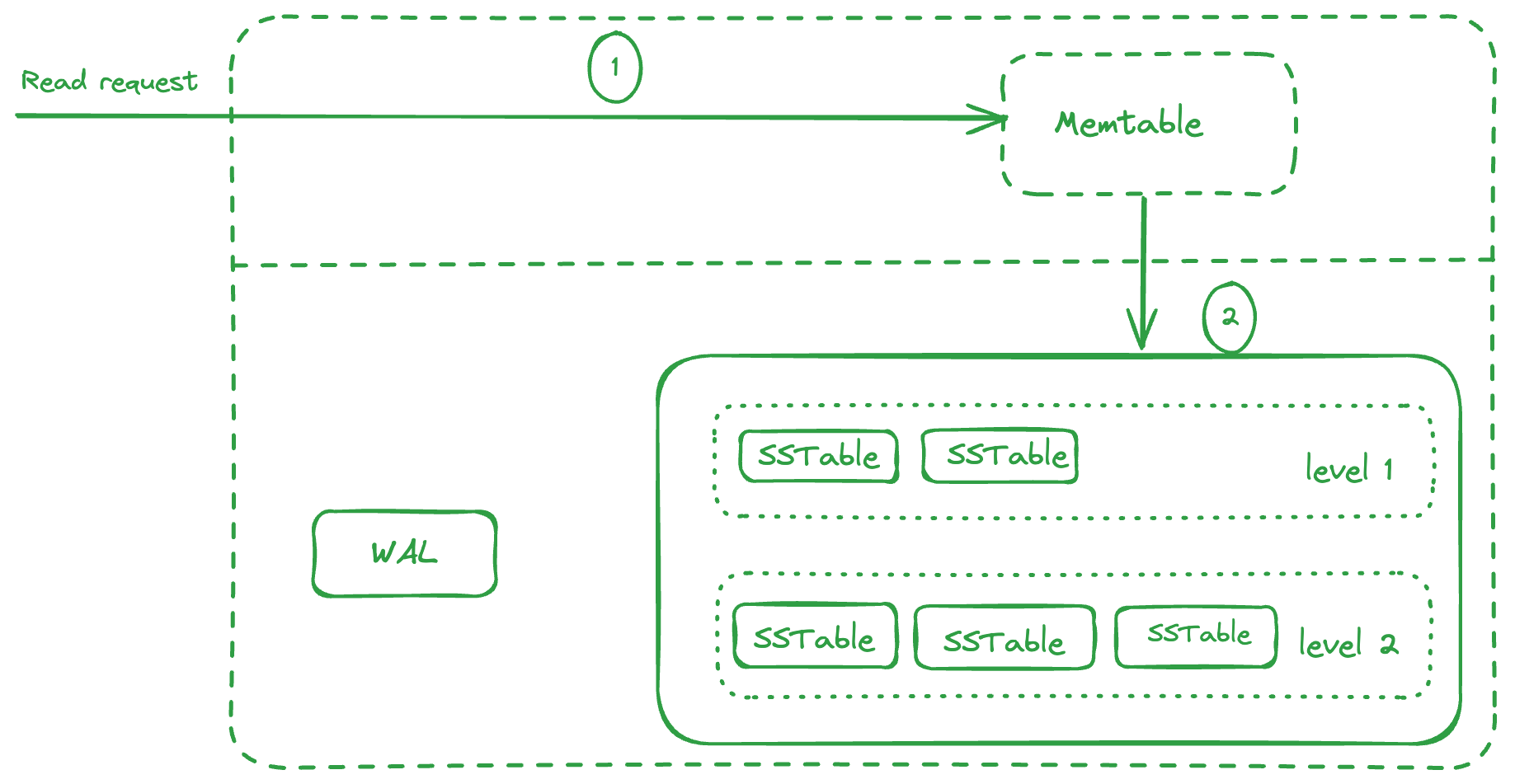
When a read request comes in, it checks the Memtable for the key, since the Memtable contains the most recent value of the key. If the key isn’t found, it goes to the SSTables level by level and check the key there. Since the SSTable is sorted by key, we can use a binary search to find the key in O(log(n)).
How to quickly find if key exists in the SSTable of a level?
We can use a bloom filter here to quickly determine if the key is present in the SSTables of a segment. Bloom filters are space efficient probabilistic data structures. They can be used to quickly determine eliminate all SSTables where key is not present.
Let’s say we want to check if a keyA is present in a SSTable. We take a 8 bit array and 3 hash functions. Each of the hash functions take a string input and return a value from 0-7.
On hashing keyA with the 3 hash functions, we get 1, 0, 5 respectively from the 3 hashes. So we set the bits at these indices. Similarly for keyB, we get 2,1,6 from the hash functions and we set these bits. Note that index 1 is already set, so we just let it remain.
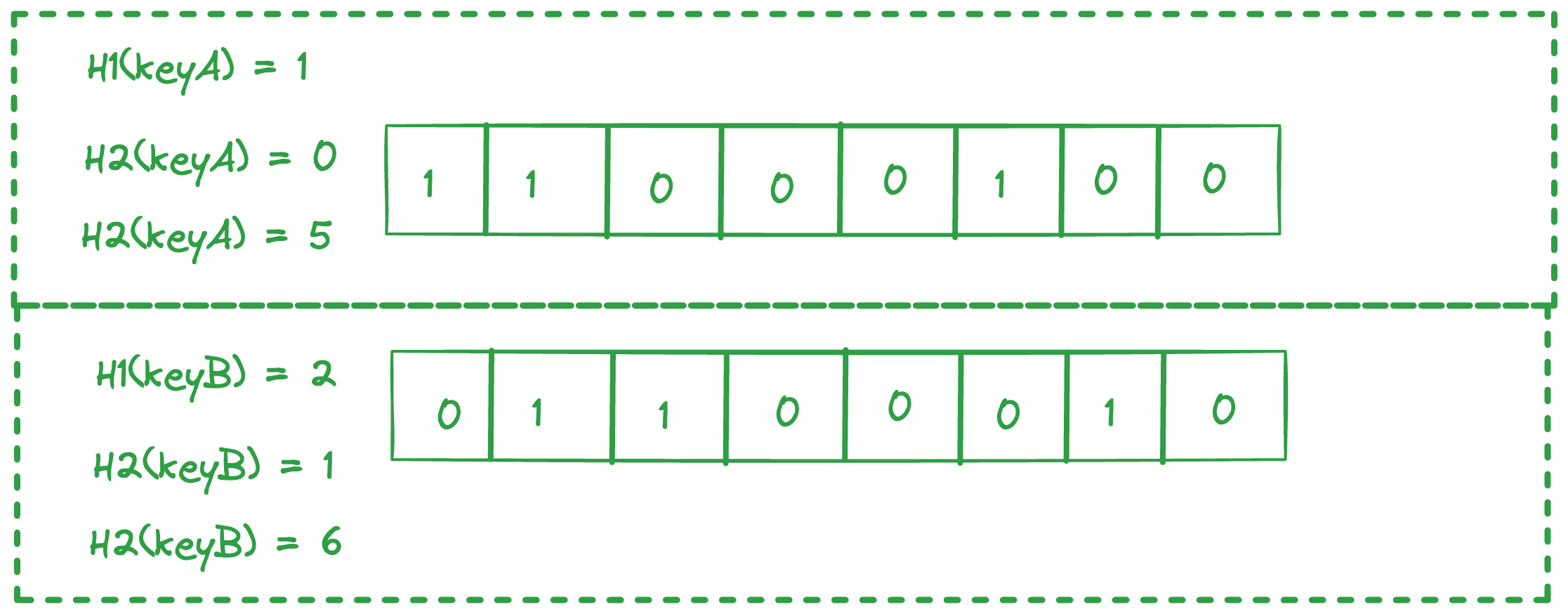
Now, for a key say keyC, we want to check if it exists in the SSTable. We will hash it with the three hash functions. Say we get 3,6,1 as indices. Now we check if the bits are set at these indices. We see 6, 1 are set, but 3 is not set. Even if one index is not set, it means the key is not present in the SSTable.
Another point to note here, is that we cannot delete any element in the bloom filter data structure.
How do we read the latest value of a key?
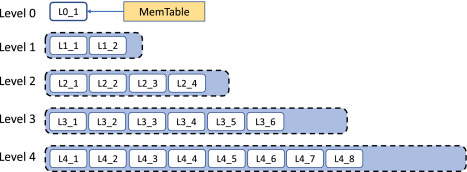
With this approach, we might be writing the same key to multiple SSTables, eg. if they occurred earlier and were flushed to a SSTable-1, and since a new Memtable was then provisioned, when the same key occured again, it was saved in this new Memtable and flushed to disk to SSTable-2 when this Memtable was full.
So while serving read request, we are now aware that the key might also be in a older SSTable flushed earlier, and as we want the latest value of the key, we start checking from the most recent SSTable segments.
The redundant keys in older SSTables can be compacted using a merge algorithm.
Compaction is the process of taking multiple SSTables, and merging them into one.
Since multiple SSTables across different levels, may have several duplicate keys, we use the latest value (from the topmost layer) and copy it to the new SSTable. Once the merging is complete, we can drop the redundant SSTables. This helps in maintaining the disk space.
How do we delete a key?
If we want to delete a key, we can add a marker to the SSTable file that signifies that the particular key is deleted. So when we merge the SSTables later, we do not include these key unless it is present in a more recent version of SSTable.
Serving Range Queries
Since the keys are now stored in a sorted manner, it is easy to serve range queries, as the keys will be adjacent.
Distributed key value store
A single-node instance is limited by its resources like CPU, memory, and disk space. To handle higher scale, we need multiple instances. Let's explore how using a distributed key-value store can help scale our system effectively.
Data Partitioning
To handle high traffic, we need to split our data across multiple instances, or partition it across multiple nodes. This partitioning cannot be done randomly, as we must ensure that reads are directed to the correct instance containing the relevant data.
One method is range-based partitioning, where keys within specific ranges are assigned to particular partitions. However, this can lead to imbalances, with some partitions being sparsely populated and others heavily loaded. To avoid this, keys should be evenly distributed across partitions.
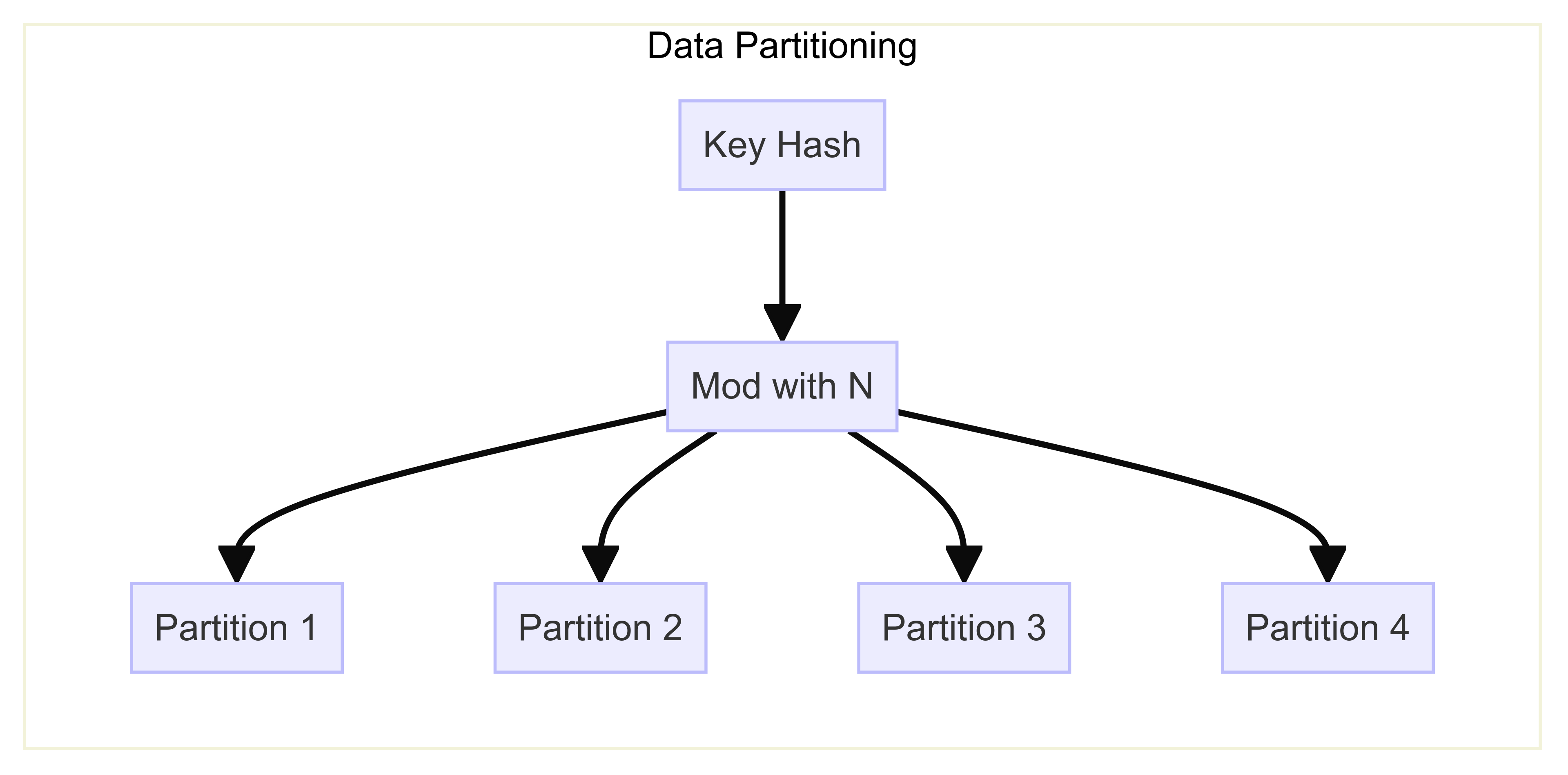
A solution is to hash the original keys using a hash function that produces randomized integer values. By taking the modulus of these values with the number of instances (N), we can assign each key a partition number. And we can store the partition in the corresponding instances. This ensures a more even distribution of data across partitions and directs reads to the correct instance.
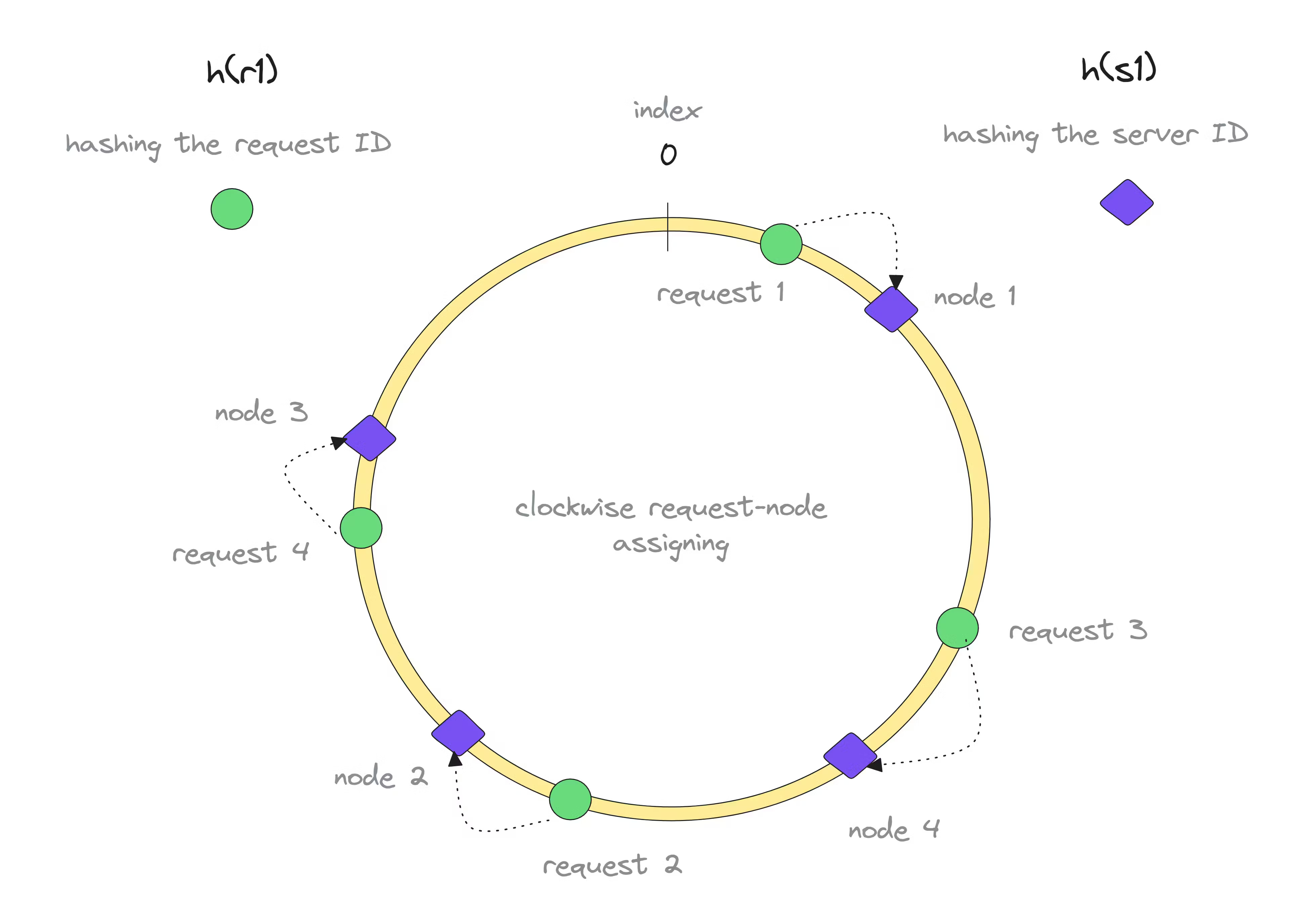
Consistent hashing
The challenge with the previous partitioning method is that adding or removing instances changes the value of N, causing all keys to be reassigned to different instances. This results in significant data movement.
Consistent hashing addresses this issue. By arranging instances on a virtual circle, we hash each key to a point on the circle. We then move clockwise to find the nearest instance. When an instance is added or removed, only its neighbouring instances are affected, minimising data movement. I talk about consistent hashing in more detail in my previous blog.
Replication and its types
Now, we have partitioned our data into partitions in different instances. Now what if one instance goes down? Our system would not be able to serve reads and writes for the keys that instance was responsible for. To avoid this scenario, we keep replicas of our data. That means, we keep the same data in different instances, so we can serve requests from the other instances in case one of them is down.
Different data stores implement this replication in different ways. We will discuss two approaches here - Leader follower replication and leaderless replication.
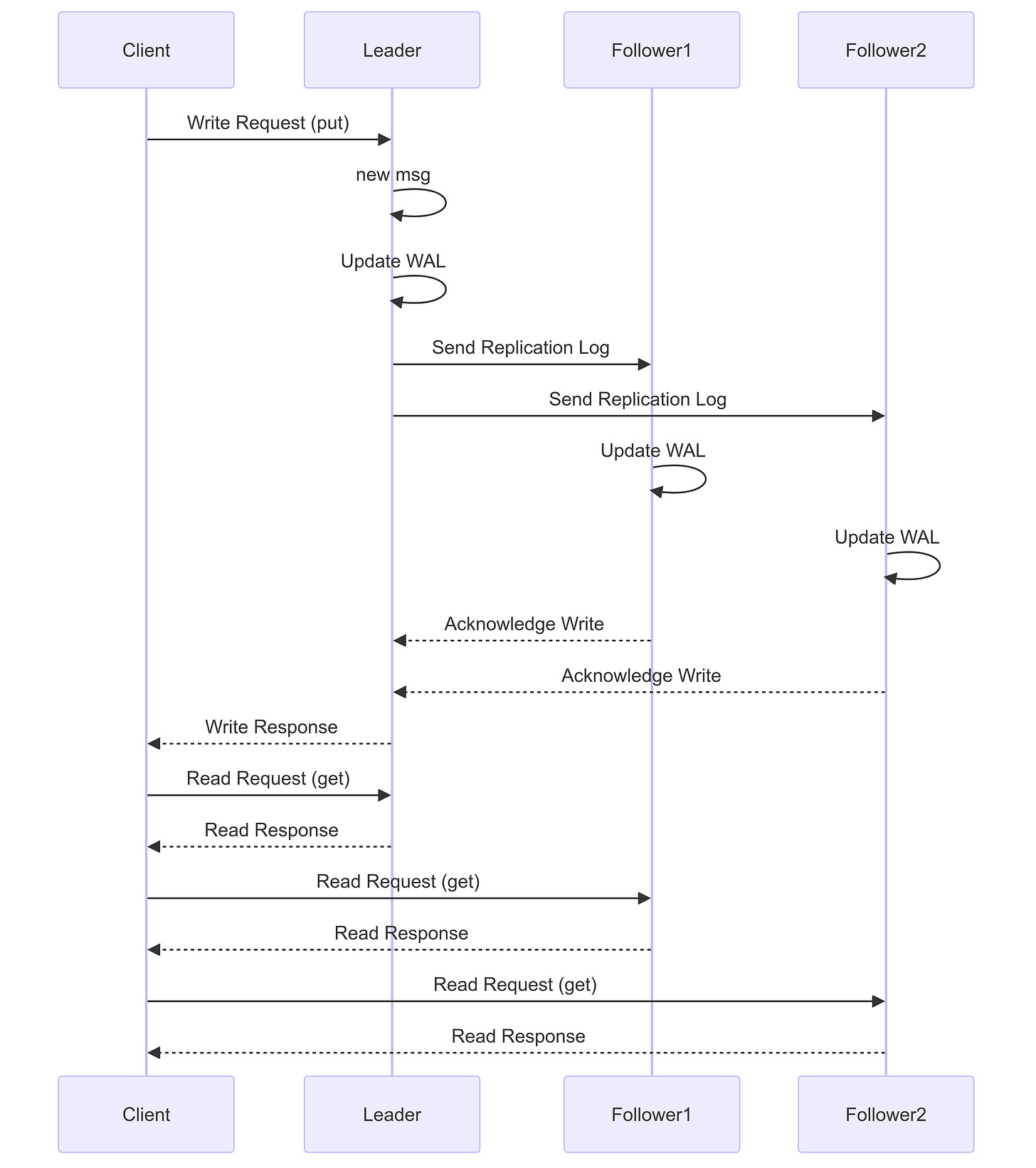
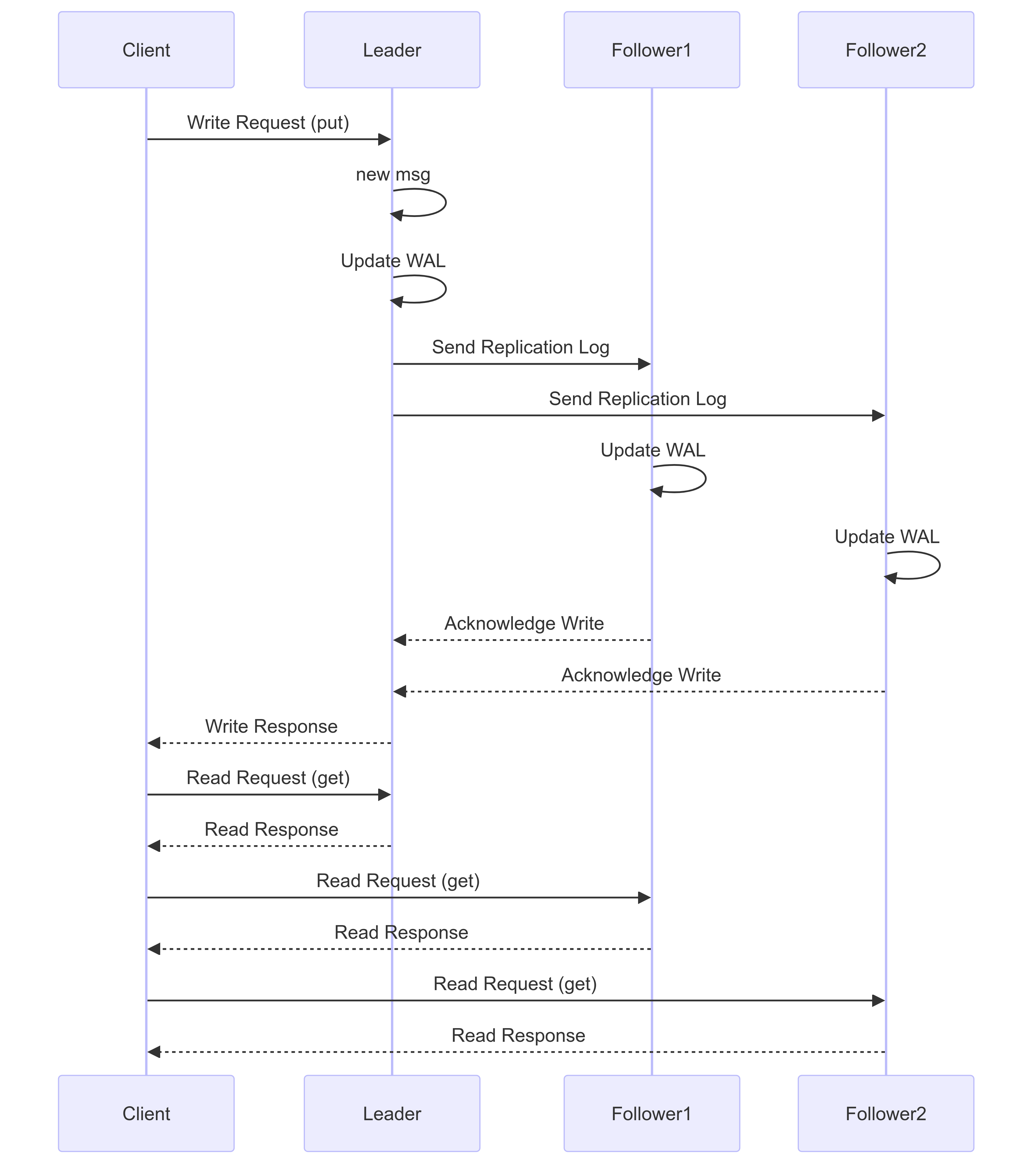
Leader Follower Replication
In leader-follower replication, one instance acts as the leader and two or more instances act as followers. Writes are handled by the leader, while reads can be handled by any instance.
Write Process
The leader records the change in its Write-Ahead Log (WAL).
The change is added to the replication log and sent to the followers.
Each follower records the change in its WAL.
Read Process
Read requests can be served by any instance, improving read scalability.
Synchronous Replication
The leader waits for an acknowledgment from all followers before responding to the client.
Consistency: Ensures strong consistency as all instances have the latest data.
Availability: If a follower goes down, the system's availability is impacted because the leader waits for all acknowledgments.
Asynchronous Replication
The leader waits for an acknowledgment from only one follower before responding to the client.
Consistency: May lead to eventual consistency, as some followers might lag and return stale data.
Availability: The system remains available even if a follower goes down, ensuring higher availability.
Leaderless Replication
In leaderless replication, any node can handle reads and writes without a designated leader. For instance, with 3 replicas per partition, a write to any node must be replicated to the other 2 replicas.
Quorum Concept
Write Quorum (W): Minimum number of replicas that must acknowledge a write.
Read Quorum (R): Minimum number of replicas that must agree on a read.
Strong Consistency: Achieved when R+W>N
Conclusion
In this article we talked about single instance key value store, and how a distributed key value store would look like. However there are several other parts to discuss for a distributed key value store including- coordinating requests, service discovery, handling partial and permanent failures, rate limiting across partitions, allowing for traffic bursts and autoscaling based on traffic, backups etc. We will discuss these in the next part of this article.